Linked Open Terms
LOT (Linked Open Terms) Methodology is a reuse-based lightweight method for developing Linked Data ontologies and vocabularies. This website will provide support for following the LOT methodology in your developments.
Please note that we are working in a more complete methodology (we are including iterations, sprints, issue tracking, etc.) and also the steps in the workflow below might be modified in next versions.
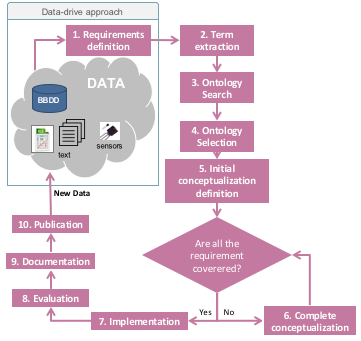
- 1. Requirement definition
This activity refers to the activity of collecting the requirements that the ontology should fulfil (for example, reasons to build the ontology, identification of target groups and intended uses). (Taken from NeOn Methodology).
These requirements can be related to the purpose of usage of the ontology, to the domain that the ontology is covering, or to technical details of the ontology, among others.
- Tools: mind map, text editor, etc
- Proposed references:
- NeOn Guidelines for non functional requirements.
- Competency Questions technique
- 2. Term extraction
-
This activity consists in identifying basic concepts and the relationships between those concepts are extracted. These extracted terms should consist of not only the terms from the data source, but also of synonyms of those terms.
The terminology might be extracted from the Competency Questions (Guidelines from NeOn Methodology or from the data, for what you might have domain expert advice.
- Tools: PoS taggers, Freeling, etc.
- 3. Ontology search
This activity consists in looking for existing ontologies that best fit the previously-extracted terms (and their synonyms). Note that this activity don't need to be carried out at this moment necessarily, it can be postpone to be done before ontology implementation.
- Tools (this is a limited list of ontology registries and indexes):
- General purpose:
- IoT
- Smart cities
- Biology
- Agriculture
- Tools (this is a limited list of ontology registries and indexes):
- 4. Ontology selection
-
During this activity, the ontologies and/or ontology elements found in the previous step that fit the ontology needs are selected. The following criteria could be used to select certain elements or ontologies:
- the semantics of the class or property in the ontology is related to the term
- if the term relates to a class, the class in the ontology has as many properties that correlate to the term as possible
- the ontology that describes the class or property related to the search term is widely accepted and used
- 5. Initial conceptualization definition
Ontology conceptualization refers to the activity of organizing and structuring the information (data, knowledge, etc.), obtained during the acquisition process, into meaningful models at the knowledge level and according to the ontology requirements specification document. (Taken from NeOn Methodology)
The aim of this activity is to build an ontology model from the ontological requirements identified in the requirements specification process. During the ontology conceptualization, the domain knowledge obtained from the ORSD document is organized and structured into a model by the ontology developers.
This step can be done for a subset of the requirements selected for the first iteration. After checking whether the model can represent all the requirements, the model would be completed if needed in the activity "6. Complete conceptualization definition".
- 6. Complete conceptualization definition
In case it is needed, complete you conceptualization in order to cover or the requirements defined or the subset of them defined for this iteration.
- 7. Ontology implementation
During this activity, the ontology development team generates computable models in the OWL language from the ontology model.
The ontology code resultant from this activity includes metadata, such as creator, title, publisher, license and version of the ontology.
- Tools: Protégé, WebProtege, TopBraidComposer...
- Recommended resources:
- Recommendations:
- Link to existing entities
- Provide human readable documentation
- Keep the semantics of the reused elements
- Provide metadata
- 8. Ontology evaluation
This activity refers to the activity of checking the technical quality of an ontology against a frame of reference. (Taken from NeOn Methodology)
- Proposed techniques/tools: (more techniques in the NeOn methodology Chapter 6)
Some aspect to evaluate ar: modelling issues, domain coverage especially for data driven, conformance with Linked Data principles, etc.
- 9. Ontology documentation
-
During this activity human oriented documentation is produced in order to facilitate its used. The HTML description of the ontology usually describes the classes, properties and data properties of the ontology. It is a good practice to include the license URI and title being used and metadata, such as creator, publisher, date of creation, last modification or version number.
- 10. Ontology publication
The aim of the ontology publication process is to provide an online ontology accessible both as a human-readable documentation and a machine-readable file from its URI. The ontology needs to be evaluated before its publication to guarantee that is ready to be used.
PhD symposium
LOT was first presented at the PhD symposium at the 9th Extended Semantic Web Conference (ESWC2012) in Heraklion, Greece.
The paper is focused on the planned research methodology and the research questions to be addressed.
OntologySummit
LOT has been presented during the OntologySummit2014 during the second session of the track Track-B: Making use of Ontologies: Tools, Services, and Techniques.
This talk was mainly focused on the identified gaps on the state of the art and the contributions LOT will provide for each activity.
OOPS!
The OntOlogy Pitfall Scanner! will be integrated in LOT.
OOPS! is a web-based tool, independent of any ontology development environment, for detecting potential pitfalls that could lead to modelling errors. This tool is intended to help ontology developers during the ontology validation activity.